Introduction
In part 3 of the article series we started looking at boot(storm) scenarios. I described the four scenarios and the environment. Also the results of the first two scenario were discussed. In this last part I will continue with the remaining boot(storm) scenarios and will compare the results of the boot scenarios with the Citrix theory.
One Site simultaneously
This scenario was defined as should not be done, but the customer would like to know what happens if it’s done. To provide the answer we should execute this one site at once scenario.
Logically the PVS servers show more resource usage as 96 Target Devices are started simultaneously. This is visible on the CPU usage and network usage. Also it’s remarkable that there is a kind of two phases in this scenario. Directly after starting device we see more resource usage and second phase after around 20 minutes were the usage is heavier again. There is also a difference visible between the 1 Gbit and 10 Gbit data centre. The higher CPU usages are longer periods on 10 Gbit, but there are less of these periods. Both networks start with a small period of 100% CPU usage, followed by several peaks of 80% to 90%. On average is 25% CPU on the 1 Gbit network and 20% on the 10 Gbit network. I must admit that I expected more CPU load, actually this won’t be a real issue if the scenario really is executed in production.
On the network part the differences are larger. The 1Gbit environment PVS server reaches a peak of 1,8 Gbit and shows a longer time of bandwidth usage against the 10 Gbit network where the peak of the Network Card is 3 Gbit. The average on 1Gbit environment is 673Mbit, while the 10Gbit is 514Mbit.
Again the memory usage and disk usage are marginal, this is logical as the bits are already loaded in the memory before, so no additional memory is required and the data is not read from the disk.
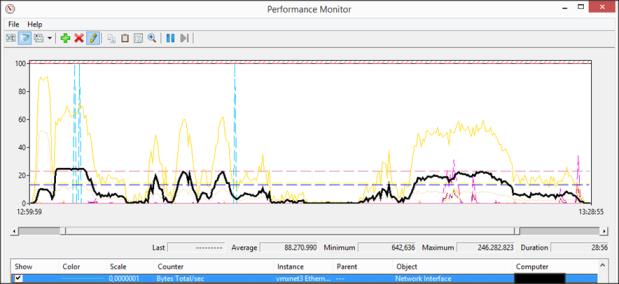
Both sites simultaneously
The last test we executed was starting all target devices (192 devices) at once. Again the customer would like to know what happens if someone will do this, while we agreed this should not be done. But what if?
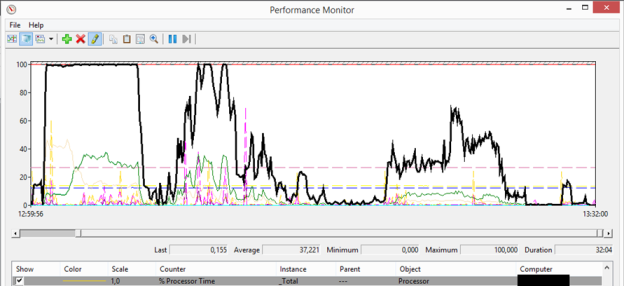
Again there were some differences noticeable between the 1Gbit and 10Gbit datacenter. At CPU level we see more a longer CPU activity in the 1 Gbit datacenter. We have a start period of 100% CPU usage, followed by several peaks of 90 to 100%. Also the average usage is significant higher around 40%/45%. At the 10Gbit data center we are seeing also a starting period of 100%, which is longer than at the 1 Gbit data center. Just as the one site test the CPU usage is average less much used; we have some peaks around 90% and 100%, but the average is around 35%/40%.
It’s becoming boring, but as expected there is again the same amount of memory usage and almost no disk usage.
However on network usage the results gave us result where we really needed to think about. Both networks are showing a peak around 3 Gbit. Comparing the averages is again difficult because the network usage of the 10Gbit datacenter drops way earlier than a 1 Gbit network (1,2 Gbit on 1GbitRC versus 662 Mbit at a 10 Gbit RC). It looks there is another factor that limits the bandwidth usage on the 10Gbit networks. To be 100% sure we did this test again on another 10Gbit datacenter with a similar set-up and also here we gained similar results on maximum bandwidth usage. Although it’s was not in scope, we would like to know why this was happening.
2 CPU versus 4 CPU
As the CPU was the only resource that was heavily used during the boot storms, we added two vCPU’s to the PVS servers and executed the boot both sites at once again. And we were right with the assumption it could be something about a lack of CPU resources. With the 4 CPUs assigned we reached a much higher maximum peak. Instead of 3 Gbit we now got a peak around 4,8 Gbit. Again we repeated this test on the similar 10Gbit data center and also this one reaches also around 4,8 Gbit. As this was out of scope of the actual tests of the customer we made our point and did not executes additional tests to dive deeper into this subject. However it’s clear there is a relation between CPU and network usage.
Results versus Theory
Also for this article series it’s interesting to compare the results of these scenarios with the Citrix Theory as described in part 1 of this article series.
We can conclude that 2 CPUs are enough for “normal” boot scenarios. Even our chosen 25 servers simultaneously are on a real safe side, I think you can start more servers without causing issues in this production environment. However we also demonstrated that CPU can influence the amount of network usage. With the 2 CPUs we are limiting the bandwidth usage to 3 Gbit, which probably is preferred by the network department. We also proved that boot storms can impact the network resources. As mentioned I would not recommended starting all target devices at once, because you are using a significant part of the network bandwidth.
The formulas used in the Citrix Virtual Desktop to determine the time required to start virtual desktops do not match the practice. We really need much more time to start the Target Devices and get a normal resource again on the PVS servers.
At last during the scenarios we have seen that the large system cache is doing his job in this environment. We don’t see any nameable disk usage and also the available bandwidth stays on the same level.
Summarization
In this article series I described the aspects around resource usage of PVS servers. We started in part 1 with the Citrix theory. In Part 2 we discussed the daily usage of three PVS infrastructure and compared the results with the theory. In Part 3 and this last part I went through the result of boot(storm) scenario and ended compared those results with the theory.