In the first part article I explained the current infrastructure and the requirements the organization had for the new environment. Instead of telling a you a perfect story and successful the project was I will describe where we went through by describing our biggest discussion points and the effect on the project.
Discussion Point 1: High Available / Disaster Recovery
The always available requirement logically arranges that High Availability and Disaster Recovery should be in place, but stated we should use the data center infrastructure (IaaS) provided by the data center division. So we started asking the options they are providing as a service. They stated that they could provide active/active, active/standby and an automated disaster recovery scenario, where the last two had their preference. However we preferred the active/active solution, because it’s has a lower cost than active/standby and is less complicated than disaster recovery. As stated it was possibility and we wrote the design on that. As the connectivity between the data centers was huge and latency was low we assumed that traffic could float between the data center without any issues (which is technically definitely possible), so we wrote our design with minimal required machines (VMs) within each data center.

As stated in the image our starting point was that it does not matter where and how data flows. So in our solution it could be that the user was connected to an Access Gateway in DC1, set-up a session on a Citrix Server in DC2, where data is accessed on a server in DC1 again or a variant on this. When we showed our design to the data center team they completed disagree with us, because they want as less possible traffic between the data centers. As we did not ask (because they offered active/active) and they did not mentioned this requirement our design did not fit. We started explaining the data streams and discussed which scenarios satisfy their requirements. It was a though discussion and we decided to regulate the traffic as much as possible although some traffic is not that much (so we did just that to comply with their rules). I will describe how we accomplished to regulate the traffic so it stays within one data center.
Traffic between CAG and XenApp Servers
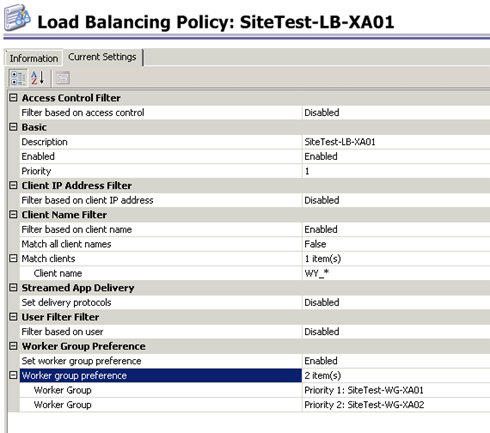
The first step was to arrange that the session between the Access Gateway and the Citrix XenApp servers would be created within the same data center. When a user is assigned to an Access Gateway in DC1 (how this will be arranged will be discussed later), the session should also be set-up on a XenApp server which is also located in DC1. I accomplished that by using adjusting the naming convention of the client machine in the Web Interface. As you probably know Web Interface by default uses a random workstation name started with WI_ . You can adjust the name convention by adjusting some code as stated in article CTX111851. We adjusted the names so it’s clear if the user is connected from an Access Gateway/Web Interface from DC1 or DC2. This client name is used with the Load Balancing Policies to assign the user to a Worker Group. Where logically the Worker Group is a group of servers located in the same data center (based on OU).
Traffic between XenApp Servers
As you know Citrix XenApp servers mutually communicates which each other. This traffic is between all servers, so a mesh technology. This traffic can be regulated by using the Zones feature in Citrix XenApp. This arranges that only the servers in the same zone communicate mutually directly, while one server in each zone communicates with the server in another zone. The amount of traffic is really low and using zones acquires more Data Collectors and makes the set-up a bit more complicated. The exact amount of traffic is stated in knowledge base article CTX114843 and as stated that low, that the data center team agreed that this amount could flow between the data centers. In other words this traffic will not be regulated, so no zones will be implemented.
Traffic between XenApp Servers and Back-end components
The last kind of traffic that should be managed is traffic out of the XenApp servers to back-end components which are hosted in the two data centers as well. As described earlier the environment is mostly used for management tasks on remote customers system, so the back-end in this environment is mainly for supporting software like RES Workspace Manager, Citrix XenApp, App-V and (supporting) File Services. I will discuss those starting with RES Workspace Manager (RES WM). RES Workspace is based on SQL database and a client (that directly communicates with the database by default). With the latest version RES Workspace Manager 2012 a new feature is added called Relay server. A relay server holds a full copy of the database and RES WM clients can synchronize with the relay server (without a connection to the database). This new feature makes it possible for us to (without SQL mirroring or similar technique) to keep the traffic within the data center. We added a relay server in each data center and the idea was to configure the XenApp servers in DC1 to connect primarily the Relay server in DC1, when this relay server is unavailable a fallback will be performed to the relay server in DC2 (and vice versa). Configuration to connect to relay server can be done via three methods (see for more information this article where the methods are explained in detail). We thought to use the preconfigured (using list option). However this option is using the configured servers in the list randomly, so there is no option to give priority affinity to each relay server (see for more information my article about RES Relay server. So to reach our goal we could not use the current options provided (while only using one relay server per data center). As a workaround we created CNAMES per data center. SO CNAME RELAYSERVERDC1 points to the relay server in DC1. If this one fails we adjust the CNAME to point to the relayserver in DC2.
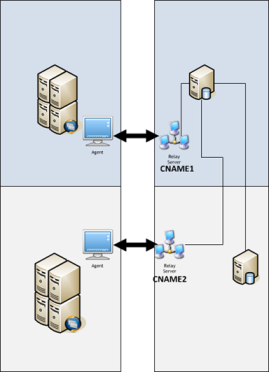
To arrange easy fall back when the primary SQL server fails (where both relay servers are pointing to this server) by using SQL mirroring, but this is only set-up for disaster recovery.
Also Citrix XenApp is using a database for storing the configuration. Every XenApp server is communicating with the database. This traffic is not that much, so we concentrated on the disaster recovery scenario only. Happily Citrix is providing an easy to configure method using SQL mirroring as described in article CTX111311. You could consider also letting the XenApp servers use the mirrored SQL as the standard database, but remember that the database is read only and changes cannot be made to the configuration from those servers.
By default App-V does not offer any load balancing mechanisms between the App-V servers. Microsoft advises to use Network Load Balancing (NLB) or use a hardware load balancer. Again one App-V server per data center would me more than enough if we could manage that the server in the other data center will only be used if the closest server is unavailable. This cannot be arranged by NLB (which is not my preferred solution anyway), so we asked the data center team for the hardware load balancer. They should have one (it was on their services list), which also could relocate servers to the closest App-V server based on IP ranges. Unfortunate this was not in place, because nobody asked for this service before. While the service was not available yet, we created a workaround using DNS CNAMES (again). For each Datacenter a CNAME was made, pointing to the App-V server in that data center. In the case the App-V server fails, the CNAME will be reconfigured to point the App-V server in the other data center.
The last component is File Services. As stated those are only used for support the other products or storing temporary files like the RES Profile Settings, Favorites and import/export functionality in the applications. To arrange that File Services traffic would be accessed by the XenApp servers out of the same data center only we configured a DFS in an active-active set-up. Because the amounts of data are relatively small, the amount of traffic is not that much and because of the way the data is begin used conflicts between open files are minimal.
Summarization
In this second part article I started describing discussion point 1 out of the list of the largest discussions which is all about minimizing the traffic between the two data centers, while still using an active/active set-up. In the upcoming article I will continue describing the other biggest discussion points during this project.